

В статье ты сможешь познакомиться с основными правилами для роботов, ознакомиться с каждым правилом более подробно и составить файл для сайта. Если после прочтения у тебя появятся вопросы или ты захочешь высказать своё мнение, то напиши об этом в комментариях и я обязательно отвечу.
Если информация из статьи будет казаться сложной, то ниже можно посмотреть видео, где поэтапно рассказывают, как создать его самому. Также я буду публиковать ссылки на сервисы, в которых можно автоматически создать файл роботс.
🤖Поехали!

К примеру директива Allow — разрешает, а директива Disallow — наоборот запрещает индексирование. Если к этой директиве добавить путь к файлу, папке или целому разделу, то это уже будет целое правило.
Приведем пример: директива Disallow: */comment — запрещает индексировать комментарий на сайте, а директива Allow: */uploads — разрешает индексировать файлы для загрузки. Но кроме этих директив бывают и другие.
Зачем скрывать содержимое сайта от поисковиков?
Дело все в том, что поисковые сервера могут проиндексировать содержимое с паролями, файлы со скриптами, плагины и остальную информацию, которая не нужна поисковикам и такое положение дел, может навредить Вашему сайту.
Более того поисковики индексируют лишние страницы и в итоге у вас образуются дублирующие страницы, за которые поисковики наказывают ваш сайт, поэтому так важно знать как настроить файл robots.
Синтаксис
Логика и структура файла robots.txt должны строго соблюдаться и не содержать лишних данных:
- Любая новая директива начинается с новой строки.
- В начале строки не должно быть пробелов.
- Все значения одной директивы должны быть размещены на этой же строке.
- Не использовать кавычки для параметров директив.
- Не использовать запятые и точки с запятыми для указания параметров.
- Все комментарии пишутся после символа #.
- Пустая строка обозначает конец действия текущего User-agent.
- Каждая директива закрытия индексации или открытия содержит только один параметр.
- Название файла должно быть написано прописными буквами, файлы Robots.txt или ROBOTS.TXT являются другими файлами и игнорируются поисковыми роботами.
- Если директива относится к категории, то название категории оформляется слешами «/categorya/».
- Размер файла не должен превышать 32 кб, иначе он трактуется как разрешающий индексацию всего.
- Пустой файл robots.txt считается разрешающим индексацию всего сайта.
- При указании нескольких User-agent без пустой строки между ними обрабатываться будет только первая
Таблица основных юзер-агентов ПС
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Директивы

Основные директивы
Существуют две основные директивы:
Allow – это директива противоположная Disallow, разрешающая поисковым роботам индексацию конкретного документа или раздела на сайте.
Allow: /wp-content/uploads/ # Разрешаем индексацию картинок в папке uploads
Disallow: /wp-content/
Disallow: /wp-content/
Allow: /wp-content/uploads/
Изображения не будут загружаться роботом Яндекса с каталога /uploads/, потому что исполняется первая директива, которая запрещает весь доступ к папке wp-content.
Google относится проще и выполняет все директивы файла robots.txt, вне зависимости от их расположения.
Так же, не стоит забывать, что директивы со слешем и без, выполняют разную роль:
Disallow: /about/ Запретит индексацию роботам страниц в каталоге site.ru/about/, а страницы по типу site.ru/about.html и.т.п. будут доступны к индексации.
Регулярные выражения
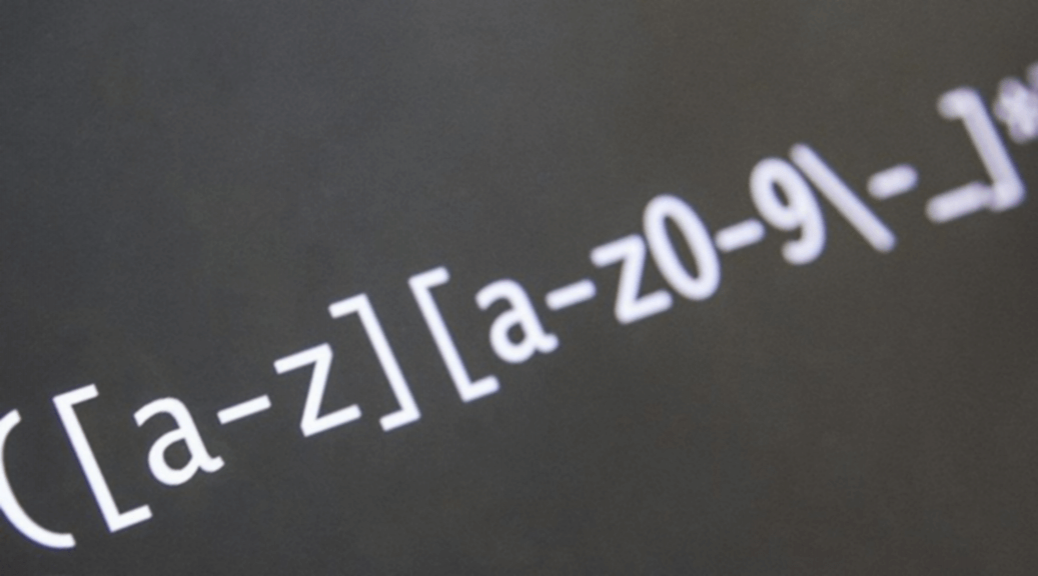
Поддерживается два символа, это:
Пример:
Например, в одной категории имеются страницы с .html на конце и без, чтобы закрыть от индексации все страницы которые содержат html, прописываем вот такую директиву:
Теперь страницы site.ru/about/live.html закрыта от индексации, а страница site.ru/about/live открыта.
Ещё пример по аналогии:
Allow: /about/*.html #разрешаем индексировать
Disallow: /about/
Все страницы будут закрыты, кроме страниц которые заканчиваются на .html
Пример:
Добавив в конце символ доллара — Disallow: /about$ мы сообщим роботам, что нельзя индексировать только страницу /about, а каталог /about/, страницы /aboutlive и.т.п. можно индексировать.
Директива Sitemap
В этой директиве указывается путь к Карте сайта, в таком виде:Директива Host
Она предназначена только для Яндекса, потому что он с помощью неё определяет главные зеркала сайта и склеивает их по ней.
Указывается в таком виде:
Host: site.ru
Без http://, наклонных слешей и тому подобных вещей. Если у вас главное зеркало сайта с www, то пишите:
Host: www.site.ru
Clean-param — Исключение страниц с динамическими параметрами
Директива Clean-param позволяет бороться с динамическими дублями страниц, когда содержимое страницы не меняется, но добавление Get-параметра делает Url уникальным. При составлении директивы сначала указывается название параметра, а затем область применения данной директивы:Простой пример для страницы http://domain.ru/catalog/?&get1=1&get2=2&get3=3. Директива будет иметь вид:
Данная директива будет работать для раздела /catalog/, можно сразу прописать действие директивы на весь сайт:
Crawl-delay — Снижение нагрузки
Если сервер не выдерживает частое обращение поисковых роботов, то директива Crawl-delay поможет снизить нагрузку на сервер. Поисковая система Яндекс поддерживает данную директиву с 2008 года.Disallow: /search/
Crawl-delay: 4
Поисковый робот будет делать один запрос, затем ждать 4 секунды и снова делать запрос.
Видео от SEMANTICAПримеры настройки файла (в раскрывающемся меню)
Если хотите скачать robots.txt, то советую сделать проще:- cоздать txt файл в блокноте;
- скопировать содержимое ниже;
- назвать файл robots.txt;
- закинуть в папку сайта;
- проверить содержимое по адресу site.ru/robots.txt.
Disallow: /admin/
Disallow: /plugins/
Disallow: /search/
Disallow: /cart/
Disallow: */?s=
Disallow: *sort=
Disallow: *view=
Disallow: *utm=
Crawl-Delay: 5
User-agent: GoogleBot
Disallow: /admin/
Disallow: /plugins/
Disallow: /search/
Disallow: /cart/
Disallow: */?s=
Disallow: *sort=
Disallow: *view=
Disallow: *utm=
Allow: /plugins/*.css
Allow: /plugins/*.js
Allow: /plugins/*.png
Allow: /plugins/*.jpg
Allow: /plugins/*.gif
User-agent: Yandex
Disallow: /admin/
Disallow: /plugins/
Disallow: /search/
Disallow: /cart/
Disallow: */?s=
Disallow: *sort=
Disallow: *view=
Allow: /plugins/*.css
Allow: /plugins/*.js
Allow: /plugins/*.png
Allow: /plugins/*.jpg
Allow: /plugins/*.gif
Clean-Param: utm_source&utm_medium&utm_campaign
Crawl-Delay: 0.5
Sitemap: https://site.ru/sitemap.xml
Частые вопросы

Как проверить работоспособность файла (валидацию)?
Это можно сделать в разделе «Инструменты для веб-мастеров» от поисковика Google или на сайте «Яндекс.Вебмастер» в разделе «Анализ robots.txt». Укажите ссылку на ваш сайт и посмотрите, нет ли ошибок. Обычно никаких проблем не возникает.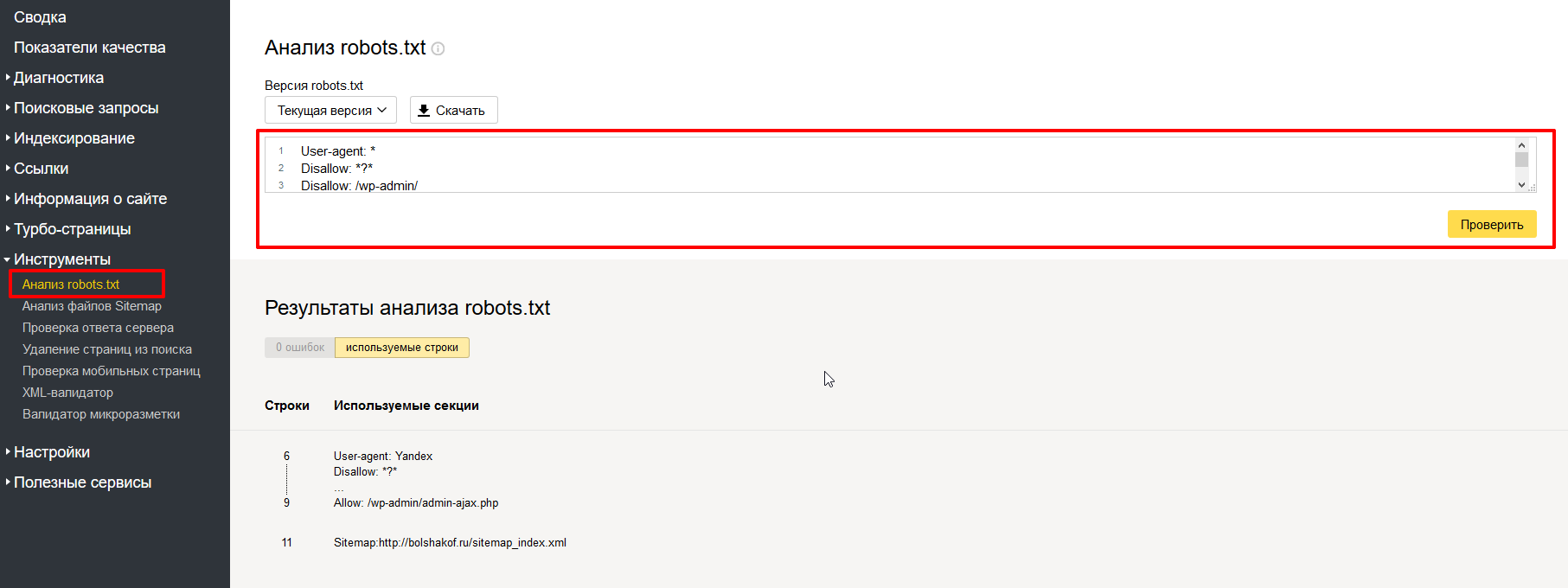
Если будут ошибки, исправьте их и проверьте еще раз. Добейтесь хорошего результата, затем не забудьте скопировать в robots.txt и залить его на сайт.
Как добавить и где находится?
После того как вы создали файл, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txtКак посмотреть у чужого сайта?
На своем и чужом ресурсе можно посмотреть файл по адресу site.ru/robots.txtНапример у Google:
Как проверить robots.txt?
Проверка осуществляется по следующим ссылкам:
В Яндекс.Вебмастере — на вкладке Инструменты>Анализ robots.txt
В Google Search Console — на вкладке Сканирование>Инструмент проверки файла robots.txt
Как закрыть весь сайт от индексации?
Disallow: /
Как закрыть сайт от индексации оставив поисковикам главную страницу?
Иногда требуется закрыть все кроме главной на сайте, для этого необходимо будет использовать регулярные вырожение и дерективу Allow.Пример файла закрывающего:
Disallow: /
Allow: /$
Как разрешить страницы пагинации к индексации и при этом запретить страницы сортировки?
Интересную ситуацию рассказа автор телеграм канала
Есть сайт и у него страницы пагинации такого типа
/accessories?page=2
и есть мусорные страницы сортировки
/accessories?page=1&sort=p.price&order=ASC
Собственно задача простая
- разрешить страницы пагинации к индексации
- запретить страницы сортировки
Имеем в роботс 2 такие строчки
Diallow: /*?* запрещает все страницы с get параметрами
и
Allow: /*?page=* разрешает индексацию страниц пагинаций
Казалось бы просто добавляем
Disallow: /*order=*
и тем самым запрещаем страницы сортировки? но это не сработало…, а вот такая строка сработала
Disallow: /*&order=*
Если кто не заметил, то добавился всего 1 символ & (амперсанд). Тут я завис. Ведь, как известно, * обозначает любой символ, в том числе и &
Так почему же Disallow: /*order=* не работает, а Disallow: /*&order=* работает?
Найти решение помогла поддержка Я.Вебмастера за что им большое спасибо, далее цитата:
На ситуацию, возникающую при добавлении символа & в правило, влияет один нюанс: директивы Allow и Disallow из соответствующего User-agent блока сортируются по длине префикса URL (от меньшего к большему). В директиве Disallow: /*order= меньше символов, чем в директиве Allow: /*?page=, поэтому приоритет остается за директивой Allow, а если добавить символ &, то у директивы Disallow будет больше символов. Если удалить директиву Allow, то запрет вида Disallow: /*order=* тоже будет работать.
Вот такая вот простая и красивая отгадка.
Если 2 директивы противоречат друг друга, одна разрешает, а другая запрещает, то приоритет отдается той, у которой больше длина префикса URL.
Как говорится век живи — век учись)
Понимает ли Google директиву Host?
Хороший ответ на вопрос я нашел на форуме вебмастеров Google.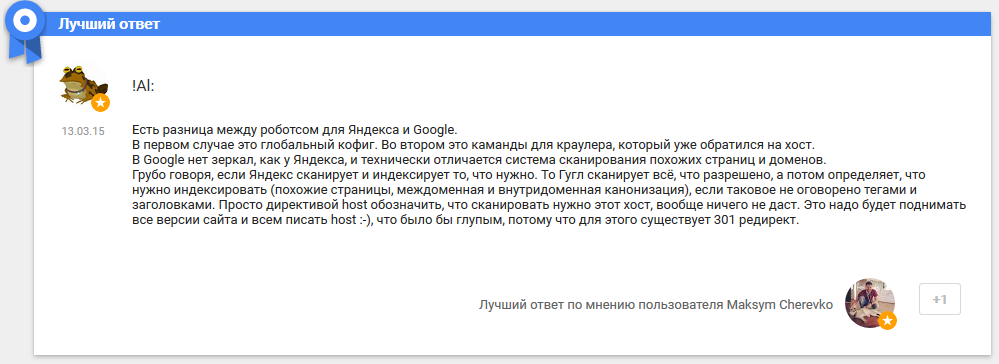
В первом случае это глобальный кофиг. Во втором это каманды для краулера, который уже обратился на хост. В Google нет зеркал, как у Яндекса, и технически отличается система сканирования похожих страниц и доменов.
Грубо говоря, если Яндекс сканирует и индексирует то, что нужно. То Гугл сканирует всё, что разрешено, а потом определяет, что нужно индексировать (похожие страницы, междоменная и внутридоменная канонизация), если таковое не оговорено тегами и заголовками. Просто директивой host обозначить, что сканировать нужно этот хост, вообще ничего не даст. Это надо будет поднимать все версии сайта и всем писать host :-), что было бы глупым, потому что для этого существует 301 редирект.
Что еще стоит закрывать?
Конечно, статья была бы далеко не полной, если бы я не рассказал, какие файлы и папки следует закрывать от индексирования.
- Страницы поиска.
- Тут кое-кто может поспорить, так как бывают случаи, когда на сайте используют внутренний поиск именно для создания релевантных страниц. Однако, так поступают далеко не всегда и в большинстве случаев открытые результаты поиска могут наплодить невероятное количество дублей. Поэтому мой вердикт — закрыть.
- Корзина и страница оформления/подтверждения заказа. Данная рекомендация актуальна для интернет-магазинов и других коммерческих сайтов, где есть форма заказа. Данные страницы ни в коем случае не должны попадать в индекс ПС.
- Фильтры и сравнение товаров. Рекомендация относится к интернет-магазинам и сайтам-каталогам.
- Страницы регистрации и авторизации. Информация, которая вводится при регистрации или входе на сайт, является конфиденциальной. Поэтому следует избегать индексации подобных страниц, Google это оценит.
- Системные каталоги и файлы. Каждый сайт состоит из множества данных — скриптов, таблиц CSS, административной части. Такие файлы следует также ограничить для просмотра роботам.
Например, фильтры в некоторых магазинах имеют свои ЧПУ, уникальные мета, контент. Конечно, не надо такие страницы закрывать — это дополнительные релевантные страницы под ключи.
Еще одно видео о robots.txt
Использование комментариев в файле
Комментарий в robots.txt начинаются с символа решетки — #, действует до конца текущей строки и игнорируются роботами.Примеры комментариев:
# Комментарий может идти от начала строки
Disallow: /page # А может быть продолжением строки с директивой
# Роботы
# игнорируют
# комментарии
Типичные ошибки
В конце статьи приведу несколько типичных ошибок файла- robots.txt отсутствует;
- в robots.txt сайт закрыт от индексирования (Disallow: /);
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла;
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий;
- в файле указаны только директивы: Allow: *.css Allow: *.js Allow: *.png Allow: *.jpg Allow: *.gif при этом файлы css, js, png, jpg, gif закрыты другими директивами в ряде директорий
- директива Host прописана несколько раз (неактуально);
- в Host не указан протокол https (неактуально);
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта;
Онлайн сервисы генерации файла robots.txt
Вы можете использовать сервисы автоматической генерации файлов роботс. Не гарантирую, что с их помощью вы создадите идеально правильный вариант, но в качестве ознакомления можно попробовать.С их помощью вы сможете создать файл в автоматическом режиме. Лично я крайне не рекомендую этот вариант, потому как намного проще сделать это вручную, настроив под свою платформу.
Говоря о платформах, я имею ввиду всевозможные CMS, фреймворки, SaaS-системы и многое другое.
Как мы увидели, хорошо настроенный файл robots поможет показать роботам, каким образом лучше взаимодействовать с вашим сайтом. Таким образом, они помогут тем, кто ищет получить более релевантный и полезный контент.









К сожалению, правило запрета к индексации страниц с фидом в конце: https://example.html/feed не помогает запретить гуглу к их индексации. Они отображаются в «Покрытие» серчконсоли в пункте «Проиндексировано, несмотря на блокировку в файле robots.txt».
Для Yandex не обязательно все тоже самое повторять, достаточно будет первой секции. У меня robots.txt попроще:
User-agent: *
Disallow: /admin/
Disallow: /profile/
Disallow: /discover/
Disallow: /search/
Disallow: /login/
Disallow: /register/
Disallow: /online/
Disallow: /staff/
Disallow: /contact/
Sitemap: http://www.site.ru/sitemap.php
На вкус и цвет все фломастеры разные 🙂
Вопрос: а зачем прятать /search/?
если можно ответ по существу, без иронии, а то самооценка и так не к чёрту)
Если в поиске на сайте что то искать, то это что то может быть проиндексировано роботом, чтоб его не мучить этим — закрываем поиск.
Если на этом сайте вбить в поиск «301 РЕДИРЕКТ» то URL получится с таким параметром:
http://bolshakof.ru/?s=301+редирект
Здравствуйте ! Народ, скажите пожалуйста, а вот для лэндинг-странички, которая расположена НА ПОДДОМЕНЕ — то для неё — robots.txt и sitemap.xml имеют какие то особенности ? И если да — то какие? Потому что основной домен я использую чисто как носитель поддоменов, и надо чтобы роботы гугла и яндекса — «видели» только эти поддомены, которые мне нужны, а не все поддомены подряд.
И где физически эти файлы должны помещаться, — в корне основного домена? Или в корне каждого нужного мне поддомена?